엣지 컴퓨팅과 인공지능의 만남은 자연스러운 진화
인공지능 기술이 점차 컴퓨팅 엣지에 해당하는 기기에서 생성되는 데이터를 실시간으로 분석하고 이를 기반으로 인사이트를 얻는 데에 활용하는 방안이 떠오르면서 엣지 컴퓨팅과 인공지능의 연계가 큰 관심을 끌고 있다.
클라우드와 사물인터넷이 처음 만났을 때는 주류 모델은 중앙 집중적이었다. 많은 기기가 단순 모델로 데이터를 코어 데이터 분석 시스템에 공급하는 일이었기 때문이다. 그러나 이제 엣지로 지능이 이동하고 엣지에 있는 시스템에서 추론과 패턴 매칭을 위해 데이터를 빠르게 처리할 수 있게 되었다. 궁극적으로 스마트 사물인터넷 기기의 시스템이나 센서는 가장 최신 데이터에 기반 해서 내부 알고리듬을 적응하는 비지도 학습을 지원할 것이다.
이는 일단 엣지 기기의 하드웨어 특히 파워와 기능의 수준이 인공지능 알고리듬을 지원할 만큼 강력해졌고, 센서들도 아주 작지만 의미 있는 메모리와 처리 능력을 갖게 되었고, 중앙 서버로 데이터를 전송할 필요가 줄어 들었기 때문이다.
특히 4차 산업혁명 흐름에 따른 사물 인터넷 기반의 스마트 공장, 스마트 모빌리티, 스마트 홈, 스마트 시티 등이 비즈니스와 기술 전략의 최전방이나 중심에 놓이면서 엣지 컴퓨팅 기기와 시스템을 통한 데이터 스트리밍 분석은 전체 네트워크에서 발생하는 이벤트의 가시성과 인지 능력을 크게 발전시킬 것이다.
딜로이트의 특별 보고서에 따르면, 사물인터넷 기기가 점점 더 스마트해지면서, 머신 러닝을 통해 자동으로 스마트 센서와 기기가 생성하는 데이터에 있는 패턴을 확인하고 이상을 감지할 것이다 [1].
이런 정보에는 온도, 압력, 습도, 공기 질, 진동, 소리 등이 포함될 수 있다. 이를 통해 예상하지 못한 가동 중단 회피, 운영 효율의 증가, 새로운 제품과 서비스 제공, 위험 관리 향상을 이룰 수 있다.
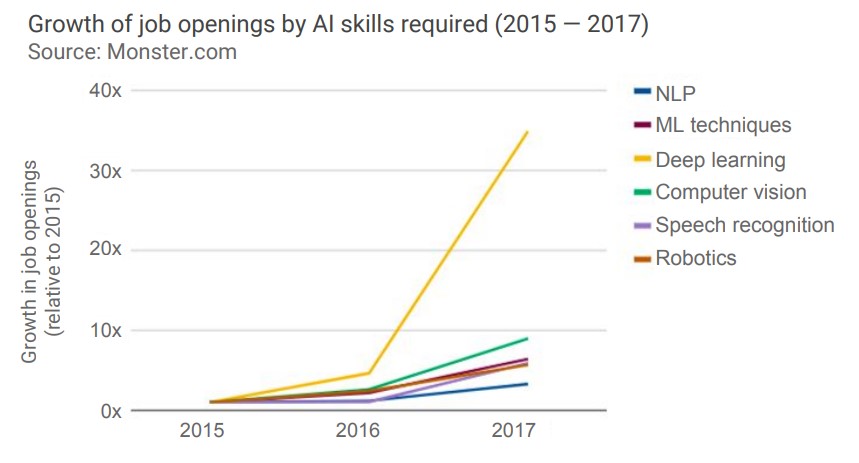
트랙티카의 보고서에 따르면 인공 지능 엣지 기기는 출하량을 기준으로 2018년 1억 6140만 개에서 2025년에는 26억 개가 되어 그 잠재성이 광범위함을 얘기하고 있다 [2].
기기 볼륨을 기준으로 보면 모바일 폰, 스마트 스피커, PC/태블릿, 헤드 마운트 디스플레이, 자동 센서, 드론, 소비자용과 기업용 로봇, 보안 카메라 순서로 규모가 클 것으로 본다. 이 밖에도 웨어러블 헬스 센서, 빌딩이나 설비 센서, 그리고 도시를 포함한 설비 전반에 심어지는 센서의 네트워크 등이 엣지 기기의 영역에 들어간다.
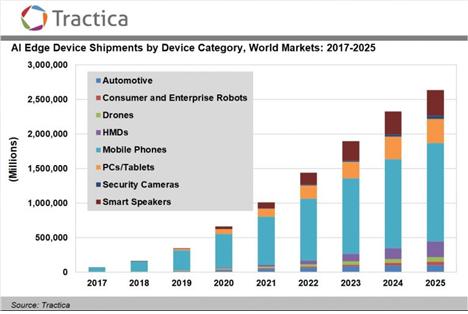
그림 1 인공지능 엣지 기기별 출하량
인공지능과 엣지 컴퓨팅이 만나야 하는 이유는 클라우드 자체의 규모가 증가하면서 지나치게 중앙화되고, 규모의 경제와 자율적 서비스는 클라우드에 내재할 수 있는 문제를 해결하는 방향이기 때문이다. 특히 엣지에서 인공지능 기능에 대한 요구는 점점 커질 수밖에 없다. 다양한 컨텍스트에서 발생하는 데이터를 이해하기 위해서는 인프라, 데이터, 애플리케이션의 요구 다양성을 다룰 수 있는 많은 플레이어가 등장해야 한다.
엣지에서 인공지능 인프라를 구축하는데 초점을 맞추고 있는 ‘스윔 AI’의 CTO 사이몬 크로스비는 모든 제조 공장이 같은 장비를 사용하더라도 내용이 달라질 수 없고, 이에 따라 하나의 모델이 동작할 수 없다고 주장한다 [3].
때로는 엣지는 클라우드에 연결되지 않을 수도 있기 때문이다. 더군다나 학습이나 실시간 결정을 위해 다량의 데이터를 클라우드로 전송하는 것이 어려울 수도 있다.
RT 인사이츠에서는 엣지에서 인공지능으로 강화된 의사 결정이 갖는 장점은 다음과 같이 정리하고 있다 [4].
- 엣지 기반의 인공지능은 매우 반응이 빠르다 – 전형적인 중앙화된 사물인터넷 모델보다 실시간에 가깝게 반응할 수 있으며, 대부분 인사이트가 같은 하드웨어나 기기 안에서 즉각적으로 전달되고 처리될 수 있다.
- 엣지 기반 인공지능은 더 강화된 보안을 보장한다 – 데이터를 보내고 받는 과정은 위험에 노출될 수 있다. 엣지에서 처리를 이런 위험을 최소화할 수 있다.
- 엣지 기반의 인공지능을 매우 유연하다 – 스마트 기기들이 에너지 관리에서 의료 모니터링 같은 산업에 특정한 또는 위치에 특정한 요구 조건을 지원할 수 있다.
- 엣지 기반 인공지능은 운영하기 위해 고도의 이론이나 고급 기술을 필요로 하지 않는다 – 자체 내에서 해결하기 때문에 인공지능 기반 엣지 기기들은 유지하기 위해서 데이터 과학자나 인공지능 개발자까지 필요로 하지는 않는다.
- 엣지 기반 인공지능은 더 뛰어나 고객 경험을 제공한다 – 위치 인지 서비스를 통한 즉응성을 가능하게 하거나, 지연이 생길 때 경로를 재구성함으로써 기업들이 고객으로부터 신뢰를 얻거나 친밀함을 갖게 만들 수 있다.
주요 클라우드 기업의 인공지능 엣지 서비스
여러 퍼블릭 클라우드 서비스 기업은 인공지능 기능을 클라우드 차원에서 제공하면서도 엣지 컴퓨팅 프레임워크에서 인공지능과 결합하는 방안을 제시하고 있다. 대표적으로 마이크로소프트는 인텔리전트 엣지라는 개념으로 일찌감치 이 영역에서 자사의 전략을 소개했다.
인텔리전트 엣지는 지속적으로 확장하는 커넥티드 시스템과 기기의 집합을 의미하며 이를 통해 최종 사용자와 가까운 곳에서 생성되는 데이터를 모으고 분석함을 가정한다 [5].
동시에 고객들에게 새로운 클래스의 분산되고 연결된 애플리케이션을 만들어 내는 능력을 제공하고자 한다.
이를 위해 애저 코그니티브 서비스 콘테이너에 대한 프리뷰를 2018년 11월에 발표했으며, 이를 통해 클라우드와 엣지를 모두 포함하는 인텔리전트 애플리케이션 제작이 가능하게 했다. 기존의 애저 코그니티브 서비스는 인공지능이나 데이터 과학 기술이나 지식을 직접 갖지 않더라도 객체 탐지, 시각 인식, 언어 이해 등의 인지 기능을 쉽게 애플리케이션에 추가할 수 있도록 한다. 이미 120만 명이 넘는 개발자들이 이를 활용했다.
이를 콘테이너로 제공하는 것은 소프트웨어나 애플리케이션이 패키지화되어 거의 수정없이 콘테이너 호스트에 채택될 수 있게 만드는 소프트웨어 배포를 위한 접근이다. 또한, 사용자들이 데이터가 어디에 있더라도 애저의 지능형 코그니티브 서비스를 사용할 수 있다는 의미이다. 이는 얼굴 인식, 문자인식, 텍스트 분석 등을 위해 콘텐트를 클라우드로 보내지 않아도 된다는 뜻이고, 인텔리전트 앱은 엣지에서나 애저에서 모두 더 큰 지속성을 갖고 이식이 되거나 확장될 수 있다는 것이다.
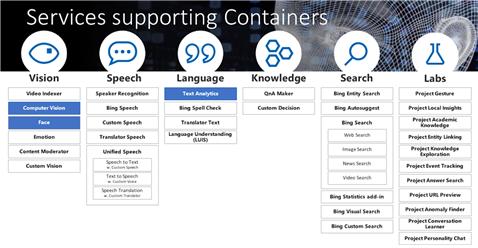
그림 2 마이크로소프트 애저의 지능형 엣지를 위한 컨테이너 서비스
사용 예로는 사이어리(Psiori)는 의료용 실험실 보고서나 이미지를 엣지에서 바로 분석해 보험 청구를 자동화 하며, 어배네이드 (Avanade)는 새로운 지능형 엣지 애플리케이션을 만들어 먼 바다의 유전 시추선 등에서 네트워크 연결이 제약을 받을 때 사용할 수 있도록 했다.
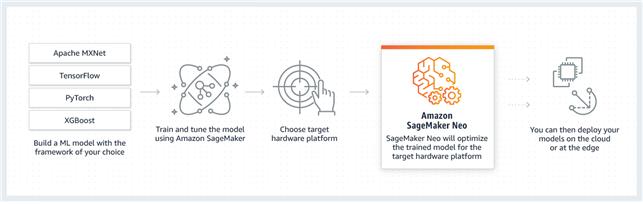
아마존은 세이지메이커 네오를 2018년 ‘리인벤트(Re:Invent)’에서 발표하면서 머신 러닝 모델를 한 번 학습시키면 클라우드는 엣지에서 이를 동작하게 할 수 있는 기능을 발표했다 [6].
머신 러닝 모델을 다중의 하드웨어 플랫폼에 최적화는 일은 쉬운 일이 아니며, 특히 엣지 기기와 같이 컴퓨터 파워나 저장 공간에 제약을 갖는 기기에서는 더 도전적인 일이다. 더군다나 소프트웨어 차이가 생기면 모델과 기기와의 호환 문제 때문에 개발자들은 모델과 딱 맞는 기기에만 적용하고자 한다.
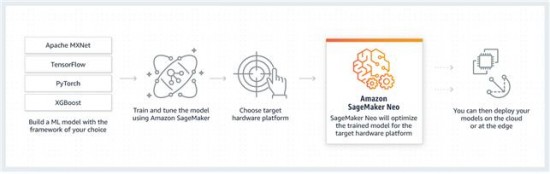
그림 3 아마존의 세이지메이커 네오 작동 방식
네오-AI는 이런 튜닝 문제를 해결해 다양한 플랫폼에서 텐서플로우, MXNet, 파이토치, ONNX, XGBoost 모델을 자동으로 최적화하고 이를 오리지널 모델보다 속도를 두 배 빠리게 한다고 주장한다. 특히 자원에 제약을 갖는 기기에서 복잡한 모델이 동작할 수 있도록 지원하기 때문에, 자율 주행차, 홈 보안, 비정상 판독 등의 영역에서 사용할 수 있다고 한다. 네오-AI는 현재 인텔, 엔비디아, ARM을 지원하며 곧 자이링스, 케이던스, 퀄컴 플랫폼을 지원할 예정이다.
네오-AI의 코어는 머신 러닝 컴파일러와 런타임 모듈이며 이는 LLVM이나 할라이드 (Halide) 기술을 기반으로 한다. 또한 워싱턴 대학에서 오픈 소스로 개발한 TVM과 트리라이트 (Treelite)를 사용하는데, TVM은 딥 러닝 모델을 컴파일하고 트리라이트는 의사 결정 트리 모델을 컴파일 한다.
네오는 아파치 소프트웨어 라이선스를 기반으로 네오-AI 프로젝트 방식의 오픈 소스 코드로 사용할 수 있다. 따라서 개발자와 하드웨어 공급업체가 애플리케이션 및 하드웨어 플랫폼을 사용자에 의해 지정하고 네오의 최적화 및 리소스 사용량 축소 기술을 활용할 수 있다.
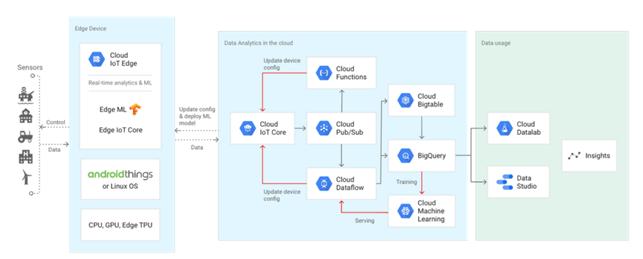
구글은 지능형 기기를 위한 제품을 두 가지로 제공한다. 첫 번째는 ‘엣지 TPU’라는 하드웨어이고, 또 하나는 ‘클라우드 IoT 엣지’라는 소프트웨어 스택이다. 이를 통해 클라우드에서 머신 러닝 모델을 구축/학습한 다음, 엣지 TPU 하드웨어 가속기의 파워를 통해 클라우드 IoT 엣지 기기에서 모델을 동작하도록 한다 [7].
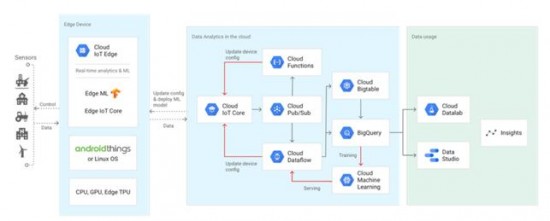
그림 4 구글의 클라우드 IoT 엣지 지원 환경
엣지 TPU는 구글이 만든 ASIC 칩으로 텐서플로우 라이트 ML 모델이 엣지에서 동작하도록 디자인 했다. 작은 면적에서 왓트 당 성능, 비용 당 성능에 최적화하게 디자인 했다고 한다. 이를 통해 클라우드에서 클라우드 TPU로 학습시킨 다음 엣지에서 매우 빠른 머신 러닝 추론을 할 수 있게 함으로써, 센서가 단지 데이터 수집기가 아닌 로컬, 실시간, 지능형 의사 결정을 할 수 있게 했다.
클라우드 IoT 엣지는 구글 클라우드의 데이터 처리와 머신 러닝 기능을 게이트웨이, 카메라 등의 최종 기기로 확장하는 소프트웨어로 이를 통해 사물인터넷 애플리케이션을 더 스마트하고 안전하고 신뢰할 수 있게 만들고자 한다. 클라우드 IoT 엣지는 안드로이드 씽즈나 리눅스 기반 기기에서 동작할 수 있으며, 주요 컴포넌트는 다음과 같다.
- 게이트웨이 클래스 기기를 위한 런타임 – 최소 하나의 CPU를 갖고 엣지에서 얻은 데이터를 저장, 번역, 처리, 지능 유도 할 수 있으며, 나머지 클라우드 IoT 플랫폼과 상호 동작할 수 있다.
- 엣지 ioT 코어 – 엣지 기기를 더 안전하게 클라우드에 연결하며, 클라우드 IoT 코어와 소프트웨어나 펌웨어 업데이트와 데이터 교환을 관리한다.
- 텐서플로우 라이트 기반 엣지 ML 런타임 – 사전에 학습된 모델윽 사용해 로컬 머신 러닝 추론을 수행하며, 이를 통해 지연을 확실히 줄이고 엣지 기기의 융통성을 증진한다.
구글이 확보한 파트너들은 반도체 회사 NXP, ARM, 게이트웨이 기기 회사 액톤, 하팅, 히타치 밴태라, 넥스콤, 노키아, 그리고 엣지 컴퓨팅 기업인 애드링크 테크놀로지, 켈빈, 올리 엣지 애널리틱스, 스마트 캣치, 트랙스 등이 있다.
참고 자료
[1] Deloitte Insights, “Intelligent IoT: Bring the power of AI to the Internet of Things,” Dec 12, 2017
[2] Tractica, “Artificial Intelligence Edge Device Shipments to Reach 2.6 Billion Units Annually by 2025,” Sep 13, 2018′
[3] Forbes, “Why AI At The Edge Is The Next Goldmine,” Apr 4, 2018
[4] RT Insights, “The Emerging Role of AI in Edge Computing,” Nov 27, 2018
[5] Eric Boyd, “Bringing AI to the edge,” Microsoft Azure blog, Nov 14, 2018
[6] Amazon, “AWS launches open source Noe-AI project to accelerate ML deployments on edge devices,” Jan 23, 2019
[7] Google Cloud Blog, “Bring intelligence to the edge with Clout IoT,” Jul 26, 2018
본 글은 한국정보화진흥원의 지원을 받아 작성되었으며, 클라우드스토어 씨앗 이슈리포트에 동시 게재합니다.